
隨著生成式人工智能持續高速發展,AI 模型規模正以前所未有的速度擴張,由數千 GPU 躍升至數萬甚至 10 萬級別。OpenAI 與 AMD、博通 (Broadcom)、英特爾(Intel)、微軟 (Microsoft)和英偉達 (NVIDIA)發表最新超級電腦網路技術 —— MRC(Multipath Reliable Connection),直指現今 AI 訓練最大瓶頸:網路傳輸效率與穩定性問題。
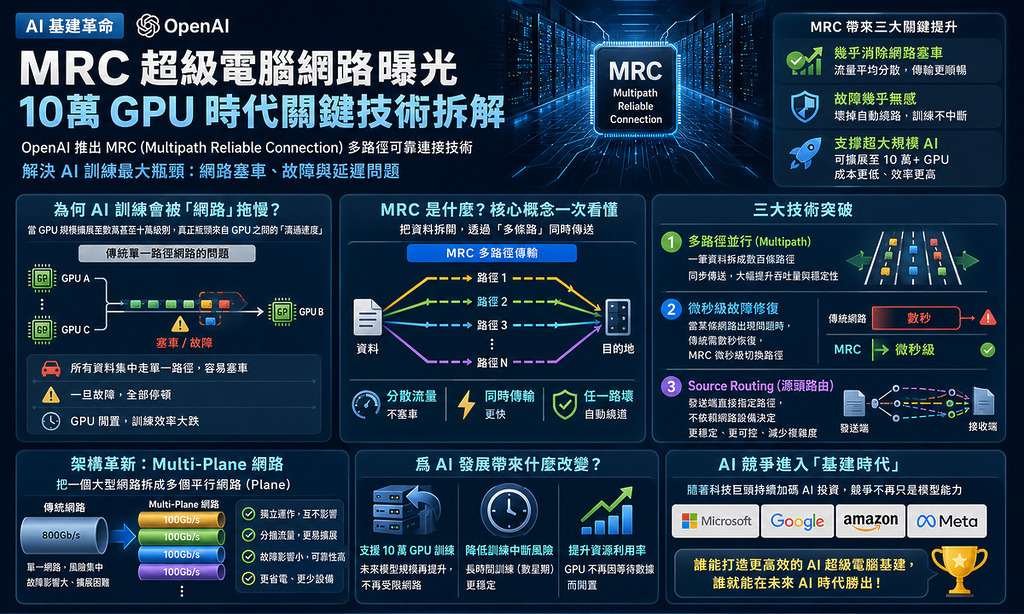
為何 AI 訓練會被「網路」拖慢?
現時每週有超過 9 億人使用 ChatGPT,OpenAI 的系統正成為人工智慧的核心基礎設施,幫助世界各地的人們和企業建立功能日益強大的模型。在訓練如 GPT-5 或更大規模的模型時,數萬顆 GPU 需要同時運算並頻繁交換數據。傳統的以太網(Ethernet)即使達到 800G 頻寬,其協議層(TCP/IP)帶來的延遲仍會導致 GPU 處於「等待數據」的閒置狀態。OpenAI 在 MRC 報告中明確指出:「網絡效率就是 AI 的生命線。」
三大技術提升穩定性與效率
MRC 的優勢主要來自三大核心設計。
首先是 多路徑並行(Multipath),讓數據可同步經多條路線傳輸,大幅提升整體吞吐量。
其次是 微秒級故障修復能力,相比傳統網路需要數秒恢復,MRC 可在極短時間內完成路徑切換,幾乎做到無感故障。
第三則是 源頭路由(Source Routing),由發送端直接決定數據傳輸路徑,減少對中間網路設備的依賴,從而提升穩定性與可控性。
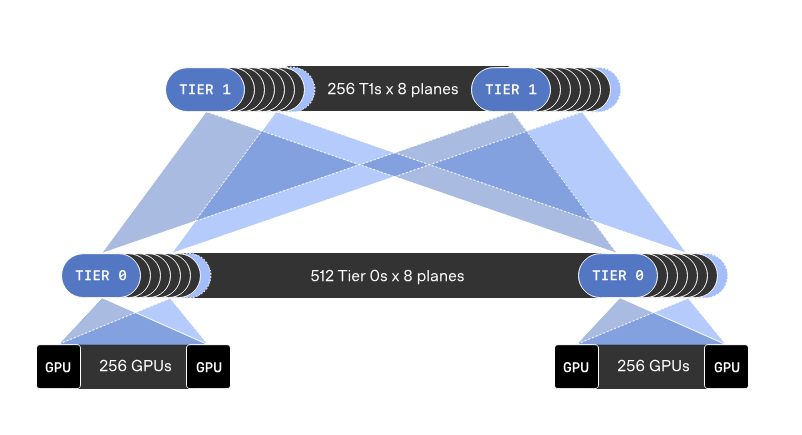
Multi-Plane 架構打造可擴展 AI 網路
除了傳輸方式革新外,OpenAI 亦引入 Multi-Plane(多平面)網路設計。
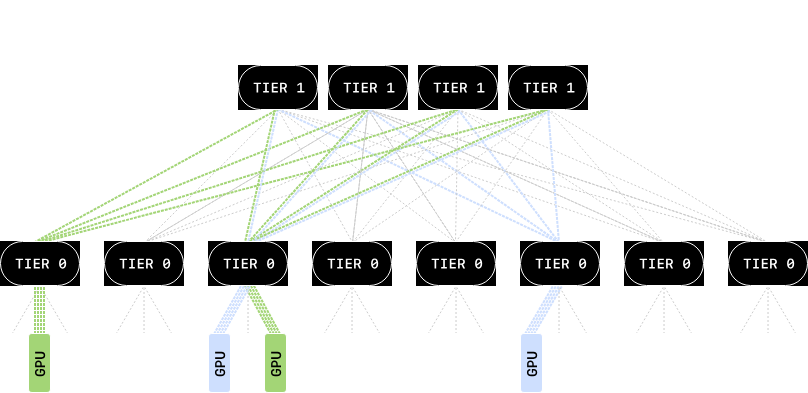
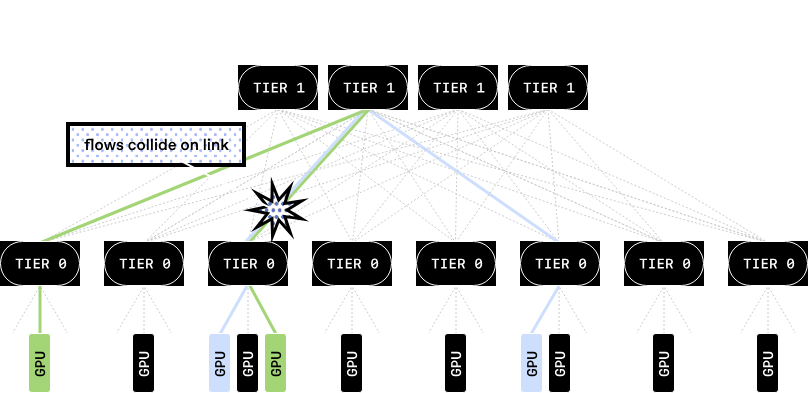
透過將流量分散到多條路徑上,MRC可以避免網路熱點,防止某些事務的耗時遠超其他事務。這可以防止影響同步AI訓練的速度下降。
簡單而言,就是將一個大型網路拆分成多個獨立運作的子網絡(Plane),每個 Plane 負責部分流量。這種設計的好處包括:
- 降低單點故障風險
- 提升整體系統穩定性
- 更容易擴展至超大規模運算環境
支撐 10 萬 GPU 訓練
MRC 架構的最大意義,在於為超大規模 AI 訓練提供穩定基礎。透過更高效的網路設計,不僅可支援 10 萬 GPU 級運算,同時亦可降低訓練中斷風險,提升整體資源利用率。
對於需要長時間運行(數星期甚至更久)的 AI 模型訓練而言,這種穩定性尤為重要。

MRC 已部署在用於訓練前沿模型的所有 OpenAI 大型 NVIDIA GB200 超級電腦上,包括位於德克薩斯州阿比林的 Oracle 雲端基礎設施 (OCI) 站點以及微軟的 Fairwater 超級電腦。 MRC 已用於訓練多個 OpenAI 模型,並利用了 NVIDIA 和 Broadcom 的硬體。如今,MRC 規範已作為開放運算專案 (OCP) 的貢獻提供給社區使用和開發。
